To manage credentials Azure Databricks offers Secret Management. Secret Management allows users to share credentials in a secure mechanism. Currently Azure Databricks offers two types of Secret Scopes:
- Azure Key Vault-backed: To reference secrets stored in an Azure Key Vault, you can create a secret scope backed by Azure Key Vault. Azure Key Vault-backed secrets are only supported for Azure Databricks Premium Plan.
- Databricks-backed: A Databricks-backed scope is stored in (backed by) an Azure Databricks database. You create a Databricks-backed secret scope using the Databricks CLI (version 0.7.1 and above).
Creating Azure Key Vault
Open a Web Browser. I am using Chrome.
Enter the URL https://portal.azure.com and hit enter.

Sign in into your Azure Account.

After successfully logging to Azure Portal, you should see the following screen.
Click on "All Services" on the top left corner.

Search for "Azure Key Vault" in the "All Services" search text box.
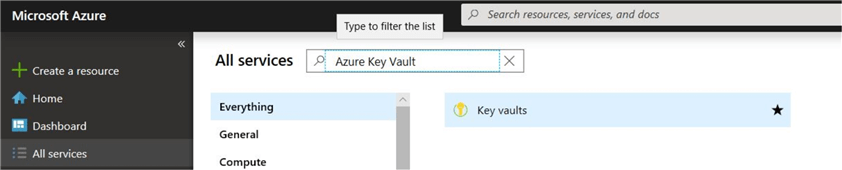
Click on "Key vaults". It will open the blade for "Key vaults".
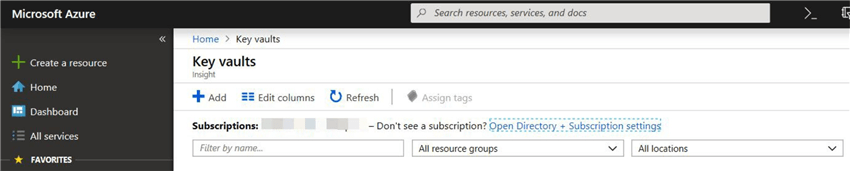
Click on "Add". It will open a new blade for creating a key vault "Create key vault".
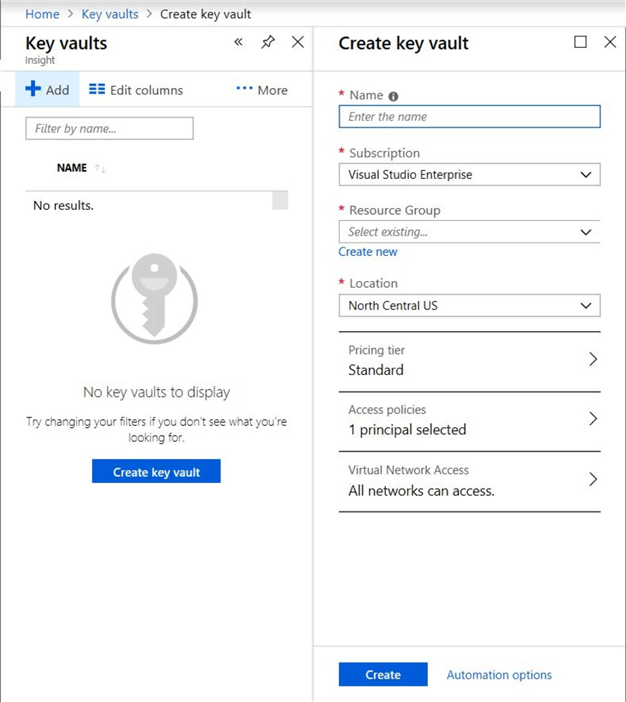
Enter all the information and click the "Create" button. Once the resource is created, refresh the screen and it will show the new "key vault" which we created.
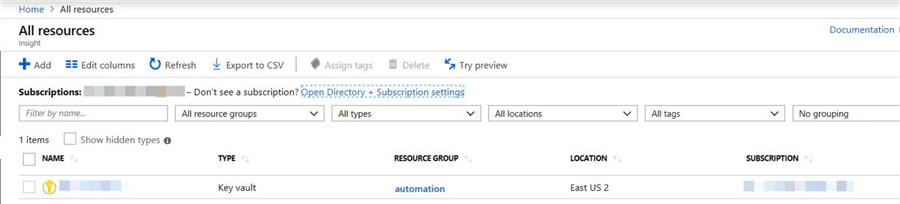
Click on the "key vault" name.
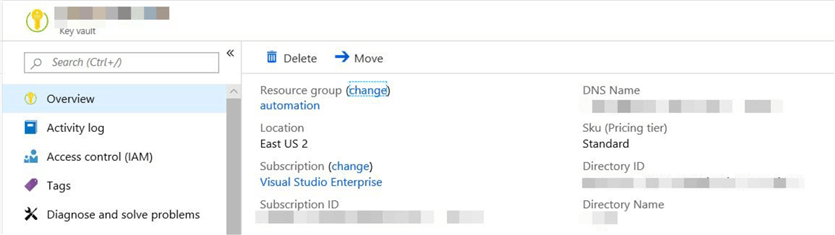
Scroll down and click on the "Properties".
Save the following information for the "key vault" created. We would be using these properties when we connect to the "key Vault" from "databricks"
- DNS Name
- Resource ID

Creating Secret in Azure Key Vault
Click on "Secrets" on the left-hand side.
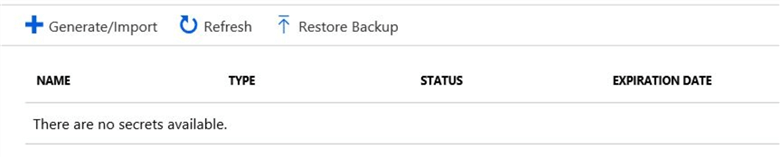
Click on "Generate/Import". We will be creating a secret for the "access key" for the "Azure Blob Storage".
Enter the required information for creating the "secret".
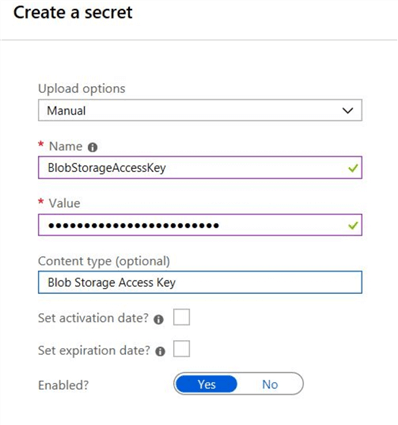
After entering all the information click on the "Create" button.
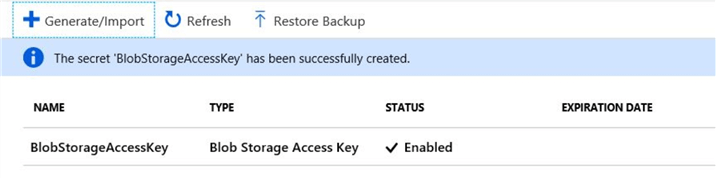
Note down the "Name" of the secret.
Creating Azure Key Vault Secret Scope in Databricks
Open a Web Browser. I am using Chrome.
Enter the URL https://portal.azure.com and hit enter.

Sign in into your Azure Account.
Open the Azure Databricks workspace created as part of the Azure Databricks Workspace mentioned in the Requirements section at the top of the article.
Click on Launch Workspace to open Azure Databricks.
Copy the "URL" from the browser window.
Build the "URL" for creating the secret scope. https://<Databricks_url>#secrets/createScope.
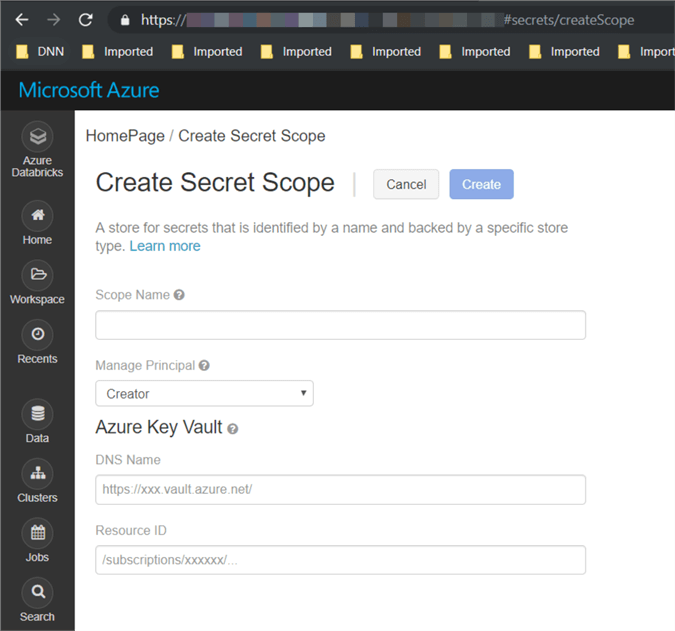
Enter all the required information:
- Scope Name.
- DNS Name (this is the "DNS name" which we saved when we created the "Azure Key Vault").
- Resource ID (this is the "Resource ID" which we saved when we created the "Azure Key Vault").
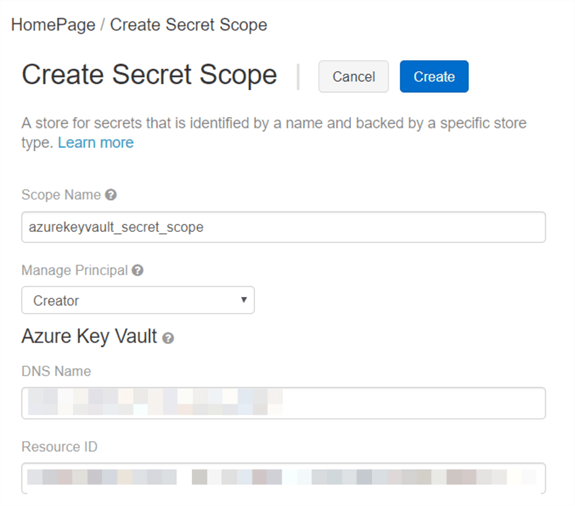
Click the "Create" button.
"Databricks" is now connected with "Azure Key Vault".
Using Azure Key Vault Secret Scope and Secret in Azure Databricks Notebook
Open a Web Browser. I am using Chrome.
Enter the URL https://portal.azure.com and hit enter.
Sign in into your Azure Account.
Open the Azure Databricks workspace created as part of the "Azure Databricks Workspace" mentioned in the Requirements section at the top of the article.
Click on "Launch Workspace" to open the "Azure Databricks".
In the left pane, click Workspace. From the Workspace drop-down, click Create, and then click Notebook.
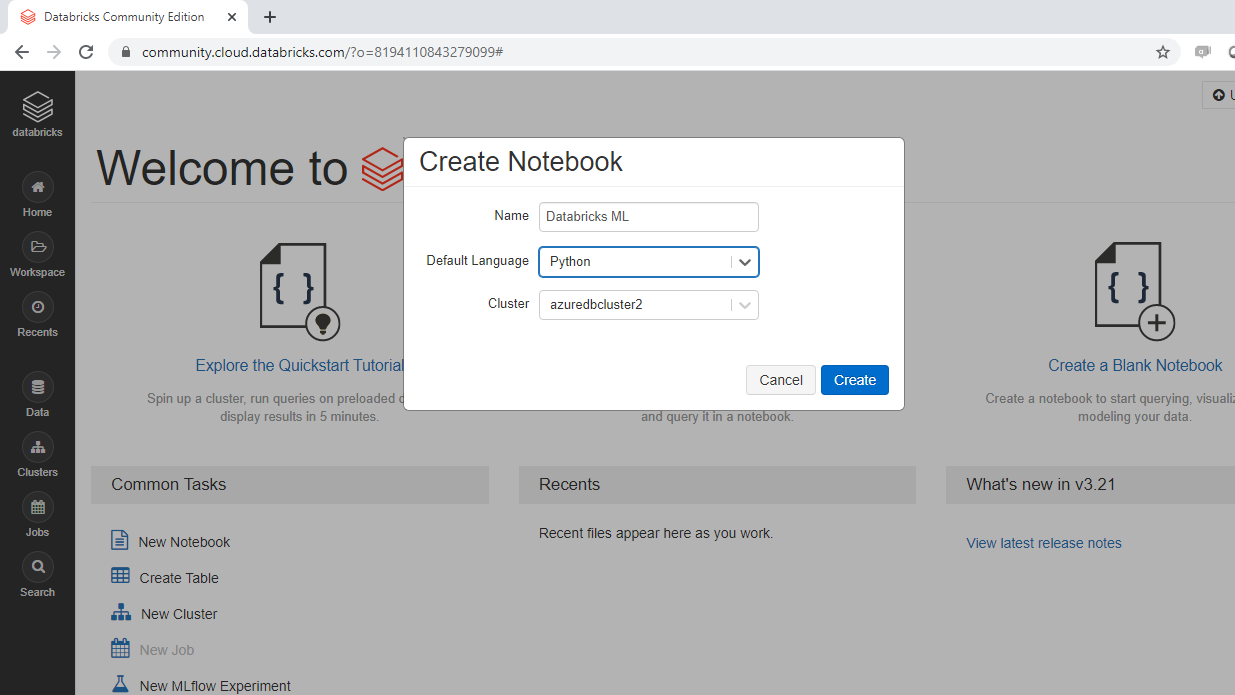
In the Create Notebook dialog box, enter a name, select Python as the language.
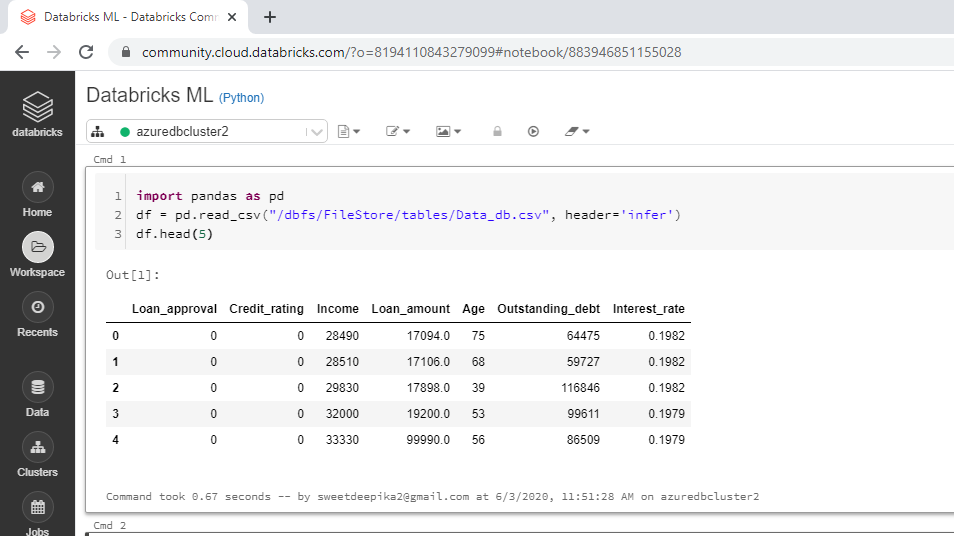
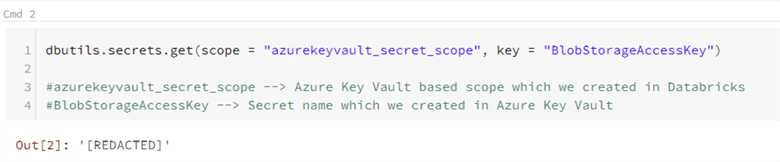
Enter the following code in the Notebook
dbutils.secrets.get(scope = "azurekeyvault_secret_scope", key = "BlobStorageAccessKey") #azurekeyvault_secret_scope --> Azure Key Vault based scope which we created in Databricks #BlobStorageAccessKey --> Secret name which we created in Azure Key Vault

When you run the above command, it should show [REDACTED] which confirms that the secret was used from the Azure Key Vault secrets.
In the same notebook we are going to add another command section and use Scala as the language.
%scala val blob_storage_account_access_key = dbutils.secrets.get(scope = "azurekeyvault_secret_scope", key = "BlobStorageAccessKey") //azurekeyvault_secret_scope --> Azure Key Vault based scope which we created in Databricks //BlobStorageAccessKey --> Secret name which we created in Azure Key Vault

When you run the above command, it should show [REDACTED] which confirms that the secret was used from the Azure Key Vault secrets.

References
- https://docs.microsoft.com/en-us/azure/azure-databricks/what-is-azure-databricks
- https://azure.microsoft.com/en-us/pricing/details/key-vault/
- https://docs.microsoft.com/en-us/azure/azure-databricks/what-is-azure-databricks
- https://docs.azuredatabricks.net/user-guide/secrets/index.html#secrets-user-guide
- https://docs.azuredatabricks.net/user-guide/secrets/secret-scopes.html
- https://docs.azuredatabricks.net/user-guide/secrets/secret-scopes.html#create-an-azure-key-vault-backed-secret-scope